
システム障害を経験した企業が
新システムに込めた教訓
復旧に向けた2つの時間
障害や災害によるシステムの停止は回避できるに越したことはないが、経験しなければ得られない学びもある。ある企業がシステム障害を引き起こした事例から、同社が得た教訓と対策を紹介する。
ソフトウェアのバグで想定外のトラブル
アウトソーシングは、製造業を対象とした人材派遣や業務請負の事業からスタートした人材サービス企業だ。「“はたらく”に国境をなくす」をスローガンに掲げて、同社のグループ企業も含めた海外拠点へのエンジニア派遣を展開。顧客企業の生産計画の変動に合わせて高度なスキルを有するプロフェッショナル人材を投入する「PEO」(Professional Employer Organization:習熟作業者派遣組織)型のアウトソーシングサービスなど、新しいサービスも提供している。
 アウトソーシングの齋藤宣裕氏
アウトソーシングの齋藤宣裕氏
国内と国外の事業を支えている同社のシステムは、プライベートクラウドやパブリッククラウドを適材適所で活用している。このうち、プライベートクラウドに、想定外のシステム障害が発生した。同社の齋藤宣裕氏(総務部 副部長、システム1課 課長、グループITI統括責任者)は、「実際に障害を経験しなければ分からないさまざまな教訓を得ました。それを基に、BCPやDRに対する考え方を抜本的に見直しました」と話す。
幸いにもこの障害の影響範囲は、グループ全社ではなく国内の一部だけで済んだものの、対象のシステムは一定時間の停止を余儀なくされた。遠隔のデータセンターでバックアップを取得し、簡易的な冗長化構成は採用していたが、ソフトウェアのバグは冗長系にも影響を与えた。事業の成長に伴ってシステムのデータ量が増大していたこともあり、バックアップからシステムを復旧させるために、想定以上の時間を費やすことになったという。
アウトソーシングで発生した障害は、仮想マシンで稼働するゲストOSのファイルシステムに論理障害が発生したことに起因するものだ。何らかの要因をトリガーにクラスタファイルシステムを利用するハイパーバイザー間で齟齬(そご)が発生し、ファイルシステムの異常を修正するソフトウェアが複数のハイパーバイザーで起動し始め、データに不整合が生じた。これが冗長系にも影響を与える障害を引き起こしたと同社は想定している。
システム障害から得た教訓とシステム要件
 InfiniCloudの瀧 康史氏
InfiniCloudの瀧 康史氏
「この障害で見えた課題の一つは、データ量が大きくなれば復旧には相当の時間がかかるということです。これはこのような障害だけではなく、自然災害によるシステム停止であっても同様に重要視すべき点です」。アウトソーシングのプライベートクラウド構築と運用を支援するInfiniCloudの代表取締役CEO兼CTO(最高技術責任者)、瀧 康史氏はこう話す。バックアップにおいては、復旧させるデータの古さを示す「RPO」(目標復旧時点)と、復旧に要する時間を示す「RTO」(目標復旧時間)という考え方がある。瀧氏は今回の障害を踏まえ、RPOだけではなくRTOをいかに短縮するかも重要視すべきだと強調する。
アウトソーシングはInfiniCloudと共に要件を整理し、DRシステムを再構築した。復旧に想定以上の時間を要した経験を基にすると、DRやバックアップに関して幾つか考え方を改めなければならないポイントもあったという。まず齋藤氏は、復旧させるシステムに優先順位付けをする「トリアージ」の難しさを指摘する。順次復旧させていく中で齋藤氏は「現在進行形で障害が発生しているときのトリアージは難しく、さらに大規模な災害時ともなればトリアージは現実的ではないと考えました」と話す。
RTOを短縮する上では、バックアップデータのコピーに時間がかかる点がボトルネックになる。そのためメインサイトにコピーバックするのではなく、障害発生時は遠隔のDRサイトに切り替えることも要件に含めた。冗長系のシステムも利用できなくなった経験から、大規模な災害など最悪の事態を想定したDRシステムを目指したという。大規模災害ではネットワーク接続にも問題が発生する可能性があるため、DRサイトが孤立した場合にもネットワーク接続を維持できる仕組みが必要だと考えた。
アウトソーシングがDRシステムの要件に含めた主なポイントは下記の通りだ。
- 大規模災害時のトリアージは現実的ではないため、DRシステムにはトリアージの必要がない規模のリソースを確保する
- 迅速な復旧のため、時間がかかるコピーバックはせずにDRシステムを稼働させる
- ネットワークの出入り口を集約すると広域の災害で接続が途切れる可能性があるため、東西のデータセンターの出入り口を自動的に切り替える
- メインサイトとDRサイトの切り替えを容易にするために、システムによっては両系が同時に稼働する仕組みでもよい
新世代DRシステムを支えるプライベートクラウド
InfiniCloudは、アウトソーシングのシステム障害や要件定義などを契機に、複数のサービス開発を進めた。RPOができるだけ新しいバックアップデータの保護と迅速なRTOを実現するため、まずは同社のプライベートクラウドの第6世代となる「VMware Private Cloud 6G」を立ち上げた。このプライベートクラウドサービスの特徴は、利便性と互換性の高いVMware製ハイパーバイザーを採用していることに加え、ストレージが独立してレプリケーションを実施する点にある。「仮にハイパーバイザーのソフトウェアスタックに論理障害が発生したとしても、ハイパーバイザーを経由せず仮想ディスクイメージのデータを救出できる利点もあり、安心感につながります」とも瀧氏は説明する。
この第6世代の、RPOとRTOに効果的な特徴は下記の通りだ。
- 関東、中部、関西の異なるリージョン間で、いつでも仮想ディスクイメージを確認したり、登録して稼働させたりできる
- スナップショットは1日に1度の頻度で14日分、1時間から3時間に1度の頻度で24時間分の差分を保持する
- 数時間前の仮想ディスクイメージをいつでも取り出すことができる
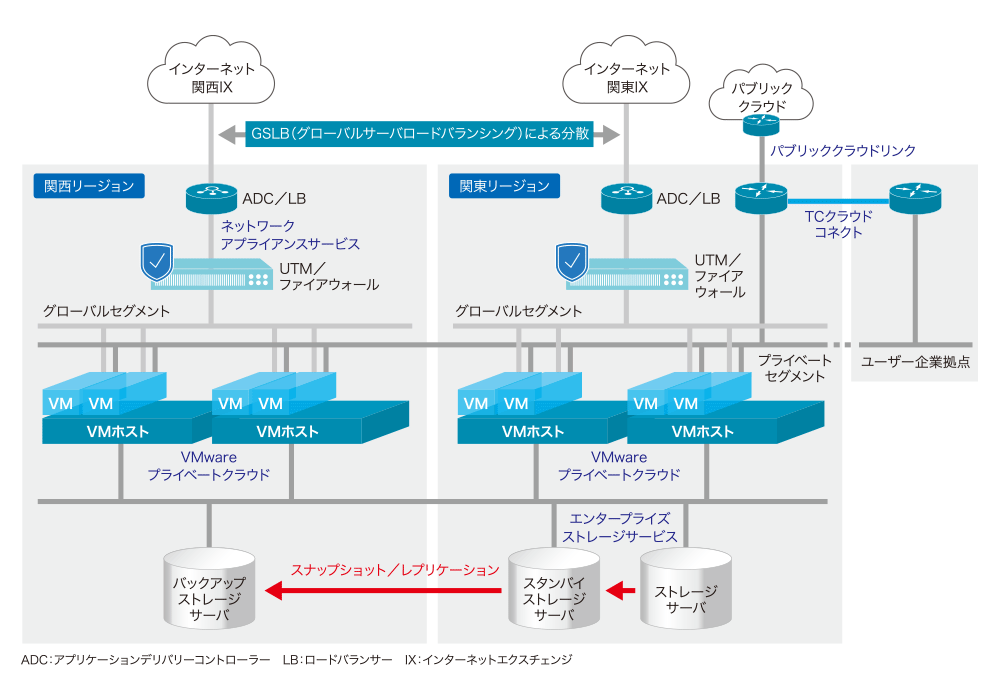
図 DR対策を改善したInfiniCloudのインフラ構成《クリックで拡大》
ストレージファブリックは、特定ベンダーのソフトウェアスタックに連動しない独立型の構造を採用した。多量の仮想マシンの収容を考慮し、ストレージは全て「NVMe」(NVM Express)によるインタフェースで組み、数十万~数百万IOPS(1秒間に処理できるデータ読み書き数)の高速な処理性能を実現している。
リージョン間を低レイテンシかつ広帯域の冗長経路で接続するネットワークサービス「インターリージョナルファブリック」も開発した。仮想マシンが接続するネットワークをレイヤー2(L2)で接続するため、異なるリージョン間でもIPアドレスを変えずに同じセグメントとして接続できる。これは復元した仮想マシンがすぐ疎通可能になることを意味するため、サービスインまでの時間短縮に効果的だ。東京の通信網が壊滅するような大規模災害も想定し、西日本のIX(インターネットエクスチェンジ)と東日本のIXに直接接続し、双方から接続可能な新たなインターネット接続サービスも設計した。
障害や災害を想定した訓練も重視
アウトソーシングの現状の業務システムは、こうしたInfiniCloudの新世代のプライベートクラウドや新たなネットワークサービスによって構築され、要件を満たした形で2019年末ごろから本格的に運用されている。齋藤氏は「新たな仕組みにしてから、システムは本当に安定して稼働しています」と話す。必要に応じて迅速にシステム復旧ができることも確認済みだが、齋藤氏は最悪の事態を想定しておくことが重要だと話す。そのため、今後はDRの「避難訓練」も計画している。障害発生の状況を想定した切り替えテストを定期的に続けて、システムの稼働状況の確認と運用担当者のスキル維持に取り組む方針だ。
ソフトウェアのバグに起因する障害は、まさに“想定外の事態”だが、実際に経験しなければ得られない気付きや学びもある。その経験を基に、迅速なシステム復旧に本当に効果的なシステム構成を組めたことは、大規模災害など最悪の事態を想定すればプラスに働いたと考えることができるだろう。
出典:TechTarget
公開日:2021年03月19日
提供:InfiniCloud株式会社(旧テラクラウド株式会社)
アイティメディア営業企画/制作:アイティメディア編集局